Introducing Wan 2.2 14b Text to Image


Alibaba released the Wan 2.2 family of video models recently, but they buried the lede: Wan 2.2 is probably the best open-source image model in the world today.
We are excited to announce we have added both Wan 2.2. text to image inference and training on fal.
Wan 2.2 is powerful image generator model. Wan is an original, raw, un-distilled model which leads to advantages over distilled image models.

Training Wan 2.2
Because Wan is not distilled, it can produce higher quality images after training then what is possible with distilled base model. Training with the fal Wan 2.2 Image Trainer could not be simpler.
Simply upload your images and hit enter and you're ready to go.
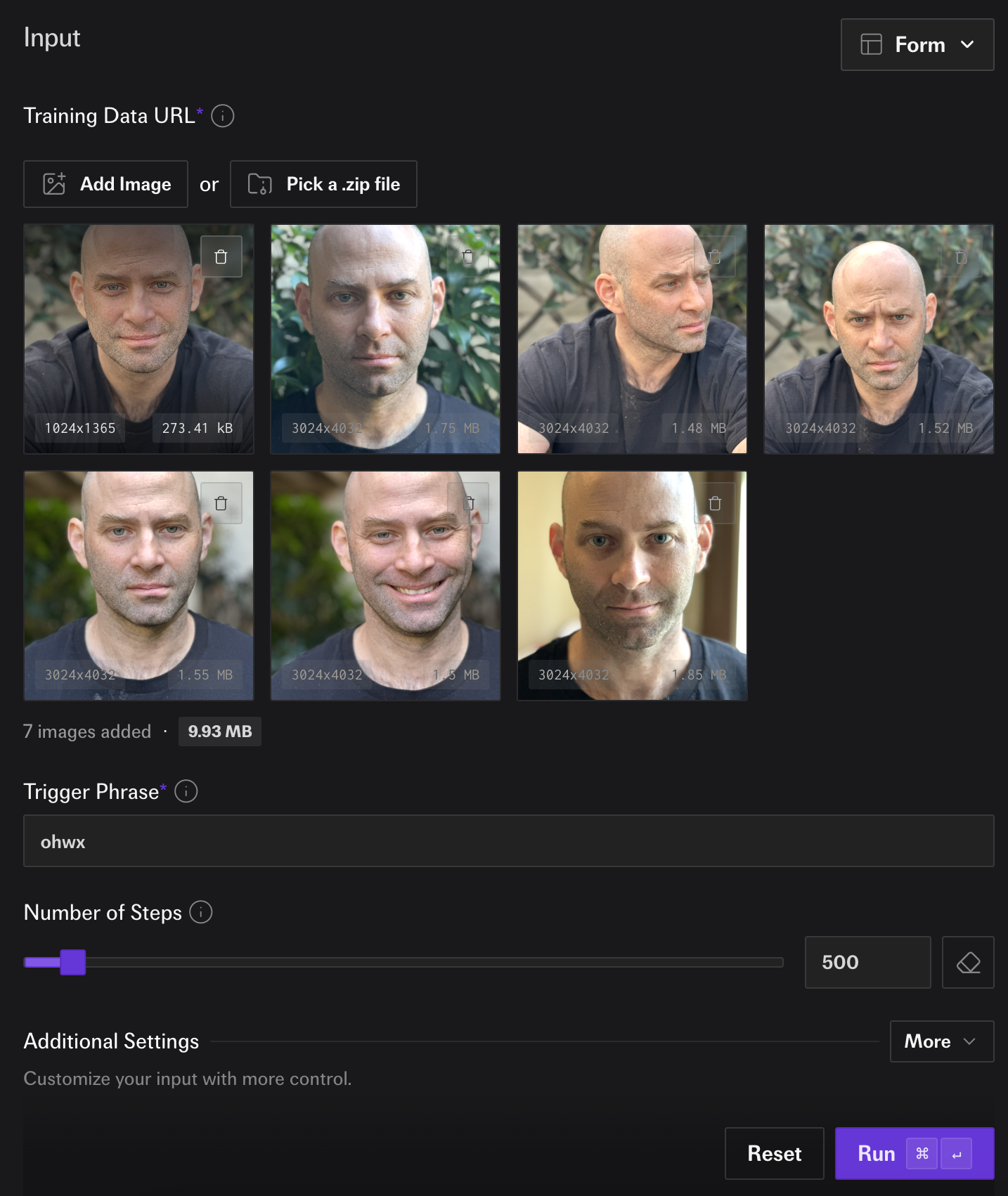
When the training is finished two LoRA links will be returned: one for the low noise transformer and one for the high noise transformer.
The fal Wan 2.2 text to image LoRA endpoint supports loading LoRAs into both transformers.
The results from Wan 2.2 training are very good. The portraits are clean, with fine grained details and excellent skin quality.

Not only can Wan 2.2 do a great job with headshots, but it can also generate small faces better than almost any image model. This opens the door to a variety of fun full body virtual photography shots.

Style Training
Not only can Wan 2.2 be fine-tuned for excellent portraits, but it excels at style training.
I used the Thomas Cole dataset I've used in previous style training blogs to train a style LoRA with the default settings, but set the is_style to true.
One of the challenges with style LoRAs is maintaining the style even if the prompt includes elements that are not associated with the style.
Wan 2.2 does well in these cases where elements of the prompt have strong photorealism associations.

New Model Who Dis?
We are just scratching the surface of what is possible with Wan 2.2. It is incredibly versatile model and we can't wait to discover how to utilize it more.
Links:


