Introducing AuraFlow v0.1, an Open Exploration of Large Rectified Flow Models

Open-source AI is in jeopardy. As community interest in AI models skyrocketed over the past year, we noticed that development of new open-source foundational models came to a halt. Some even boldly announced that open-source AI is dead. Not so fast!
We are excited to present you the first release of our AuraFlow model series, the largest yet completely open sourced flow-based generation model that is capable of text-to-image generation. AuraFlow is a reaffirmation of the open-source community's resilience and relentless determination.


Auraflow is exceptionally good at prompt following. Prompt1: "A photo of a beautiful woman wearing a green dress. Next to her there are three separate boxes. The Box on the Right is filled with lemons. The box in the Middle has two kittens in it. The Box on the Left is filled with pink rubber balls. In the background there is a potted houseplant next to a Grand Piano." Prompt2: "a cat that is half orange tabby and half black, split down the middle. Holding a martini glass with a ball of yarn in it. He has a monocle on his left eye, and a blue top hat, art nouveau style
How do I use it?
If you want to try out a few quick prompts, go to fal’s model gallery to start playing around.
If you want to build some cool Comfy workflows with the model, get the latest version of Comfy and download the model weights from our HuggingFace page.
We would love to give a huge shout out to ComfyUI and the HuggingFace 🤗 diffusers 🧨 teams for supporting AuraFlow natively on Comfy and diffusers on day 0!

How this collaboration happened
Simo is one of our favorite researchers in the wild world of generative media models. You may know him from the amazing adaptation of the LoRA paper for text-to-image models. Few months ago, Simo wanted to implement MMDiT from scratch, and see if he would be able to reproduce it. His initial attempts at https://github.com/cloneofsimo/minRF and its initial result Lavenderflow-v0 came out to be promising. Soon, he found various aspects that could be optimized to train the model on a larger scale more efficiently.
Timing couldn’t have worked out better. Right around this time, we were convinced that a SOTA open-sourced model is the way forward for this space to move forward. We wanted to bring serious resources and compute to scale up the model. We were aligned very well, and thus begun the collaboration.
AuraFlow demonstrates that collaborative, transparent AI development is not only alive but thriving, ready to tackle the challenges and opportunities of tomorrow's AI landscape.
Technical Details
Here, we wanted to share some initial technical details that stand out. We are planning on following up with a more detailed report and possibly a paper as well.
1. MFU as a first-class citizen
Most layers don’t need MMDiT Blocks: While MMDiT achieved good performance, we found that removing many layers to just be single DiT block were much more scalable and compute efficient way to train these models. With careful search in the small-scale proxy, we’ve removed most of the MMDiT blocks and replaced them with large DiT Encoder blocks. These improved the model flops utilization at 6.8B scale by 15%.
Improved training with torch.compile: At fal, we are already big fans of Torch Dynamo + Inductor, and build on top of this tooling (with a custom dynamo backend) to run our inference workloads super fast (and efficiently utilizing the underlying hardware). Since PT2’s torch.compile is able to handle both forward and backwards passes, AuraFlow’s training was further optimized with its primitives on each layers forward method, and further able to improve MFU by extra 10% ~ 15% depending on the stage.
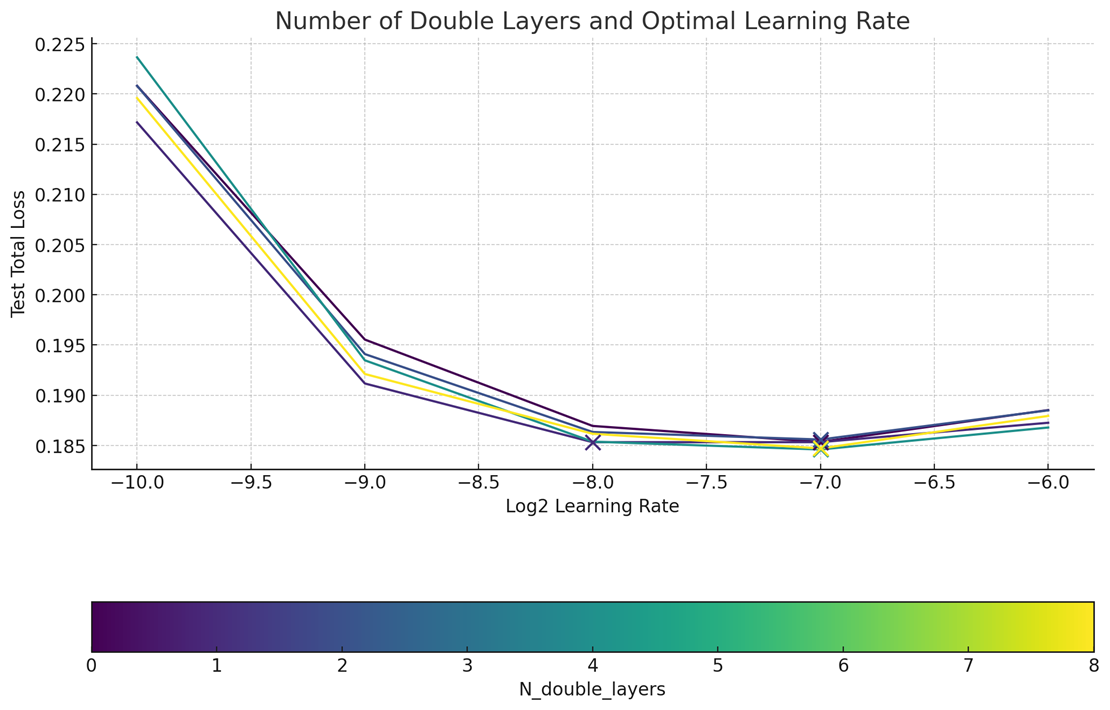
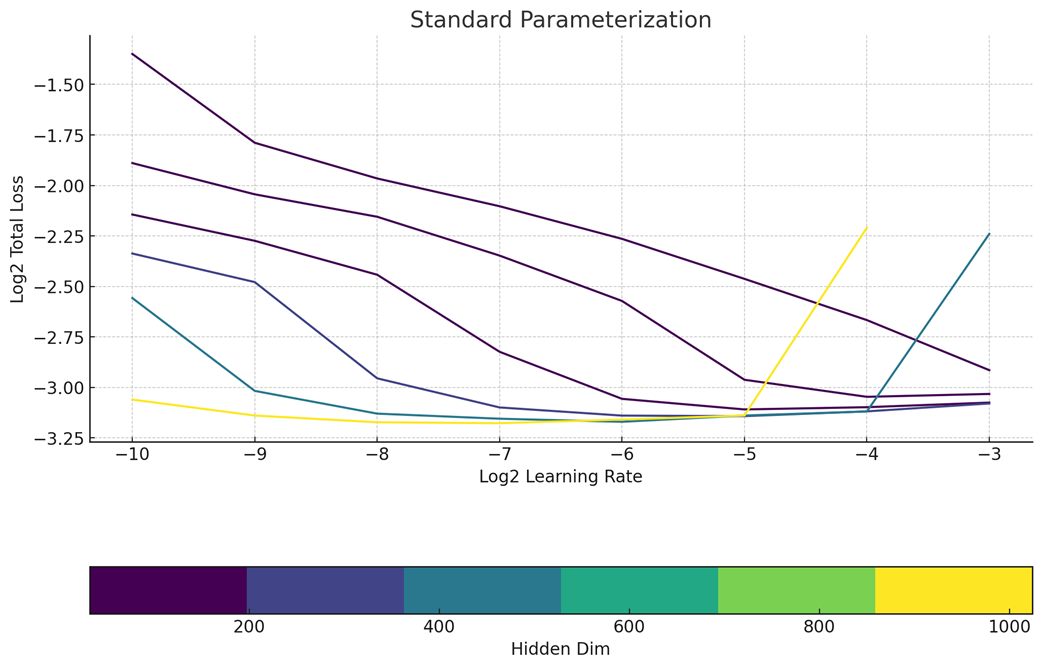
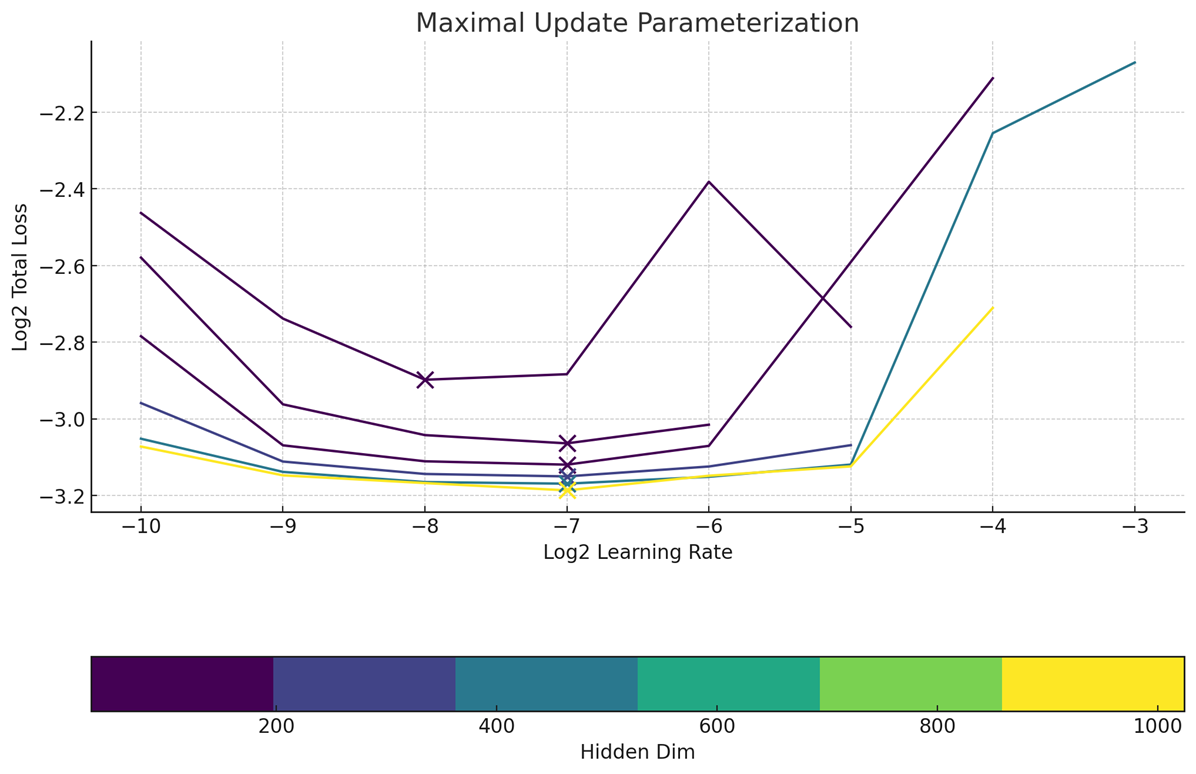
2. Unlock zero-shot learning rate transferIt is clear that we are not Meta, and would like to have very good hyperparameters even without sweeping them. Fortunately, we noticed MMDiT architectures were also zero-shot LR transferred with maximal-update-parameterization was utilized.Compared to SP, muP was clearly the winner in terms of predictability of learning rate at scale.
3. Re-captioned, everything.It is common trick to recaption everything to make sure there are no faulty text conditions in the dataset. We used our in-house captioner & external captioned dataset to train these models, which improves the quality of the instruction-following significantly. We followed the DALL·E 3 approach to the extreme, and we had no captions that were alt-texts.
4. Wider, shorter, better!To further investigate the optimal architecture, we were interested into making a fatter model, i.e., making the architecture overall utilize largest matmul divisible by 256. This lead us into searching for optimal aspect ratio under optimal learning rate found by muP.With these findings, we were confident that aspect ratio of 20 ~ 100 is indeed suitable at larger scale, which was similar with findings from Scaling Laws for Autoregressive Generative Modeling. We ended up using 3072 / 36, which resulted in model size of 6.8B parameters.
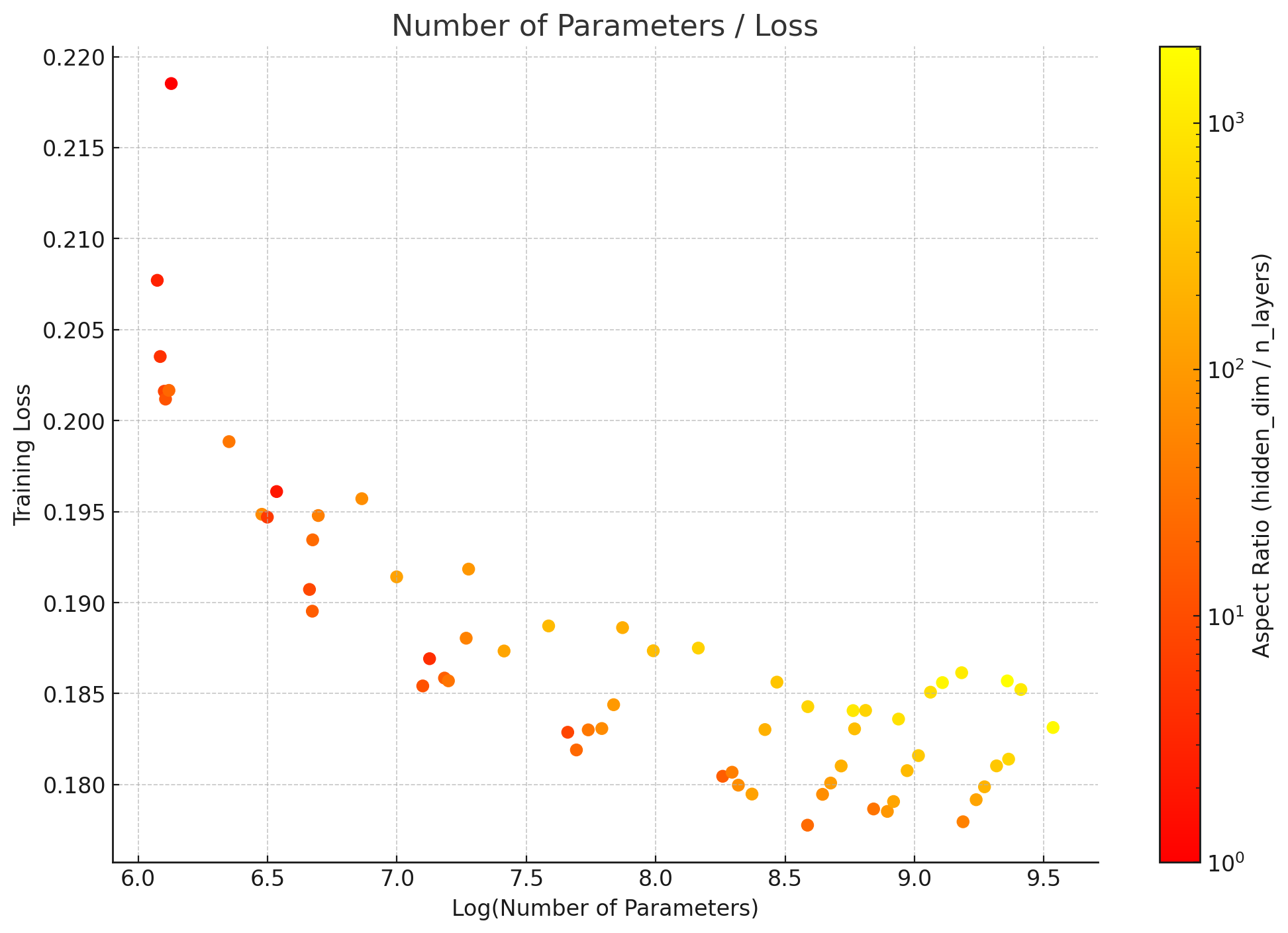
In the end, we did the best of our ability to improve and effectively find the optimal configurations for large scale training. Utilizing the findings from above, we were able to train a text-to-image model from scratch in our largest possible settings for 4 week of compute time, including 256x256, 512x512, 1024x1024 pre-training and aspect ratio fine-tuning. Final model achieves a GenEval score of 0.63~0.67 during pretraining, and similarly 0.64 after 1024x1024 pretraining. But with prompt-enhancement pipeline similar to DALL·E 3, we were able to achieve 0.703!
Prompt for prompt-enhancement
A caption is a way that a person would describe an image separated by commas when necessary. All in lower case. Expand the input below into a more detailed caption without changing the original relative positions or interactions between objects, colors or any other specific attributes if they are disclosed in the original prompt. Clarify positional information, colors, counts of objects, other visual aspects and features. Make sure to include as much detail as possible. Make sure to describe the spatial relationships seen in the image. You can use words like left/right, above/below, front/behind, far/near/adjacent, inside/outside. Make sure to include object interactions like "a table is in front of the kitchen pot" and "there are baskets on the table". Also describe relative sizes of objects seen in the image. Make sure to include counts of prominent objects in the image, especially when there is humans in the image. When its a photograph, include photographic details like bokeh, large field of view etc but dont just say it to say something, do it only when it makes sense. When its art, include details about the style like minimalist, impressionist, oil painting etc. Include world and period knowledge if it makes sense to, like 1950s chevrolet etc.
Challenges of distributed training on multi-modal data
One of the harshest realities of training image models is that, unlike LLMs, the modality of the data itself can be a real pain to deal with. During AuraFlow’s training, we leveraged our expertise from dealing with distributed storage as well as managing a large fleet of thousands of GPUs.
Some of this expertise was directly transferable from production grade inference/fine-tuning systems, where we were able to use open source projects like JuiceFS and some were more novel challenges like how do you stream massive amounts of data in and out of multiple nodes while leveraging local NVME space as a staging ground to not to reduce the MFU.
Be on the lookout for a detailed post on how we choose our storage mediums, where we trained this model, how we evaluated GPU performance and managed large clusters!
What is next?
We are not done training! This model is an initial release to kickstart some community engagement. We will continue training the model and apply our learnings from this first attempt. We also noticed that smaller models or MoE’s might be more efficient for consumer GPU cards which have a limiter amount of compute power, so follow closely for a mini version of model that is still as powerful yet much much faster to run. In the meantime, we encourage the community to experiment with what we are releasing today.
Our goal is to make this model a standard backbone that other innovative work can be built on top of. We look forward to community contributions. If you want to train finetunes, IP-Adapters, or quantizations of the current model, we are happy to support you in any way we can. There is already a vibrant community around fal and Aura models in our Discord. We invite you to join if you want to get involved.
For business inquiries, please email us at hello@fal.ai 😄