Training FLUX Style LoRA on fal


FLUX has taken over the image generation space, but getting exactly the style you want can be difficult. This where style LoRAs can help.
Training a style LoRA on Fal is easy, but there are some tips and tricks for getting the best results.
The Basics: Collecting a Good Dataset
The key to a great style LoRA is a great dataset. Some qualities to look for:
- High resolution images, ideally 1024x1024 or greater.
- Images with no compression artifacts or noise.
- Consistent images that represent the style well.
It is possible to use images low resolution but you need to make sure that there is no compression or other degradation. The benefit of collecting very high resolutions images is that when they are resized during training, compressions artifacts and other imperfections will be lost.
Thomas Cole Style
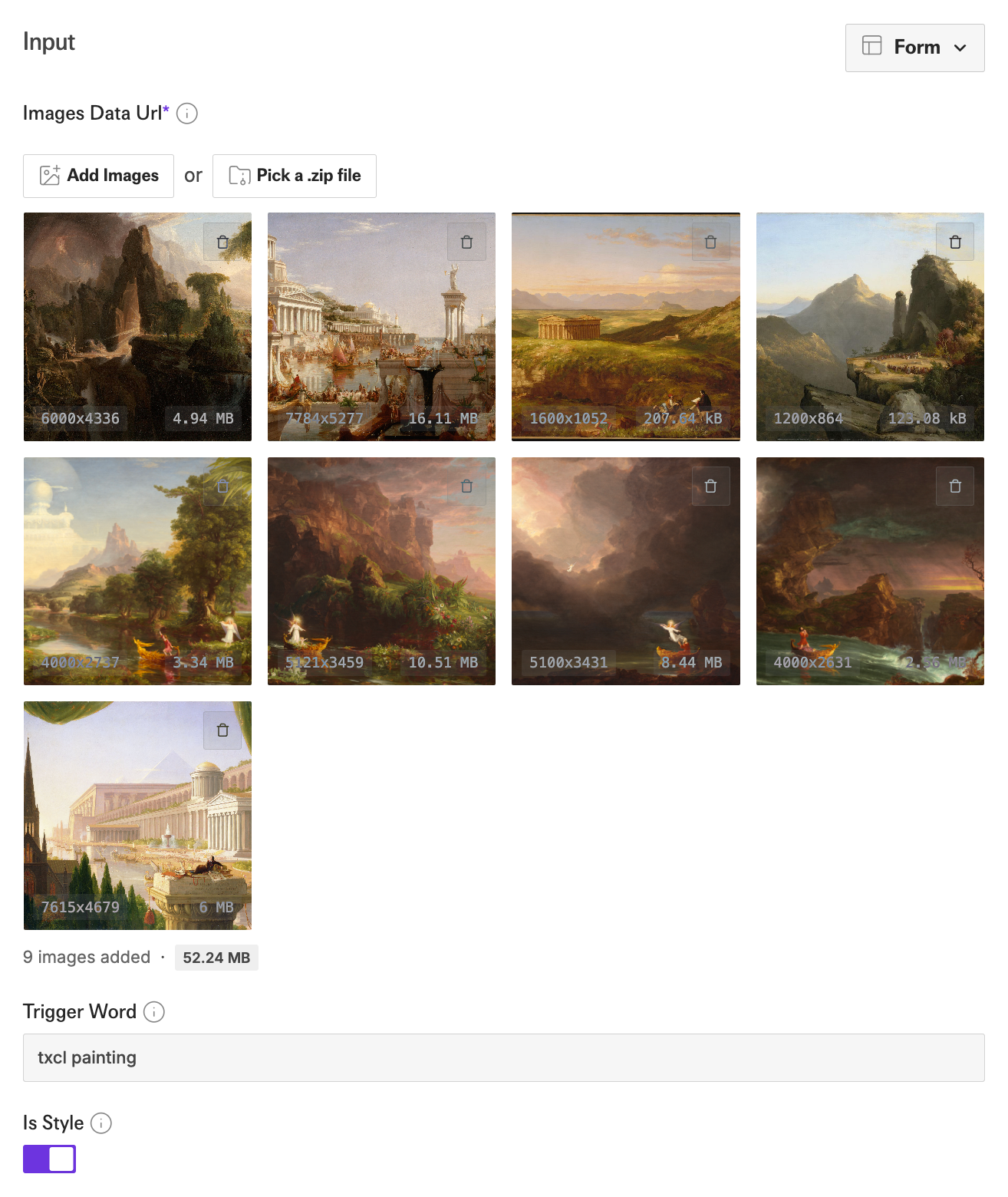
As an example, we’ll walk through creating a style for the 19th century American painter Thomas Cole. I collected nine images of his on Wikimedia that look like this:

How Many Images Are Enough?
On first blush the answer to how many images to collect is, as many as possible. However there are a few things to watch out for.
A greater number of images will allow one to train longer, getting a better represented style, but only if a few things are true.
First, you need high quality images. It is often better to have a smaller number of very high quality images then a large amount of low quality images. So make sure when adding images you don’t let the quality drop.
Additionally, as you increase the data set, be sure that each image accurately represents the style. Adding a diverse dataset of similar but distinct styles can make it difficult to learn the style well without significant training, if at all.
For the Thomas Cole example I have collected nine very high resolution images (primarily 4k), which is sufficient for creating a nice style LoRA in this case.
Captioning Take 1
Captioning is a subtle art. How one captions the images will have a large influence on the ability to capture the style when generating with prompts later.
For style LoRA training our we want to associate the style with a short phrase and describe novel scenes with that style.
We accomplish this by associating the style with a “trigger word” or more accurately a trigger phase.
When using the Fal FLUX LoRA Trainer we should enter a trigger phrased like “txcl painting” for the trigger_word parameter.
Additionally we will use the is_style option. This disables auto-captioning and segmentation masks which we don’t want for style training.
Here is what our training options look like:
After training with the prompt txcl painting we get:

Great! It looks like a Thomas Cole and isn’t an exact reproduction of the training data.
A quick note on my choice of trigger phrase. In general you want to use a unique token like txcl to be able to prompt the style irrespective of other LoRAs you might use. I find that FLUX is biased to photographic styles as well, so I will add in a class description, painting in this case, to help it not produce a more realistic image.
Step Count
By default the Fal FLUX trainer uses 1000 steps. This is a good starting point, but the ideal step count is hard to know in advance.
The goal with style training is to train long enough to reproduce the style, but not so long that the model loses the ability to follow creative prompts.

The LoRAs were trained with step counts of 500, 1000 and 2000 from left to right.
When we train with too few steps we lose the style. However if we overtrain, we lose the ability to properly follow prompts. As you can see, by the time we train for 2000 steps we can no longer prompt a cat with lasers shooting out of its eyes. Just total garbage.
The perfect step count is hard to know ahead of time. It depends on how many images your dataset has and how diverse the images are. It also is dependent on how much you want elements in the prompt to be represented vs the style.
The best approach is to train for multiple steps accounts and try different checkpoints and choose the one that best serves your particular prompting needs.
Captioning Take 2
Using the default values for the Fal FLUX trainer worked great, but if we do some manual work we can improve upon our initial result.
Instead of just using the default approach of merely trigger_word (or more accurately the trigger phrase) for our captions, we can use a more complex captioning approach to increase our prompt following and style transfer.
The issue with just using txcl painting for the caption is we are associating everything in the image with that phrase. Ideally, we would want to only associate the style with txcl painting and not the content. This will allow us to train longer and us use more diverse prompts.
To weaken the association of the subjects, we will create custom captions that describe each image, but we will be careful to not describe the style. We want the style to be associated with txcl painting.
To accomplish this custom caption task I used https://fal.ai/models/fal-ai/any-llm/vision. Here is what my example input looked like:
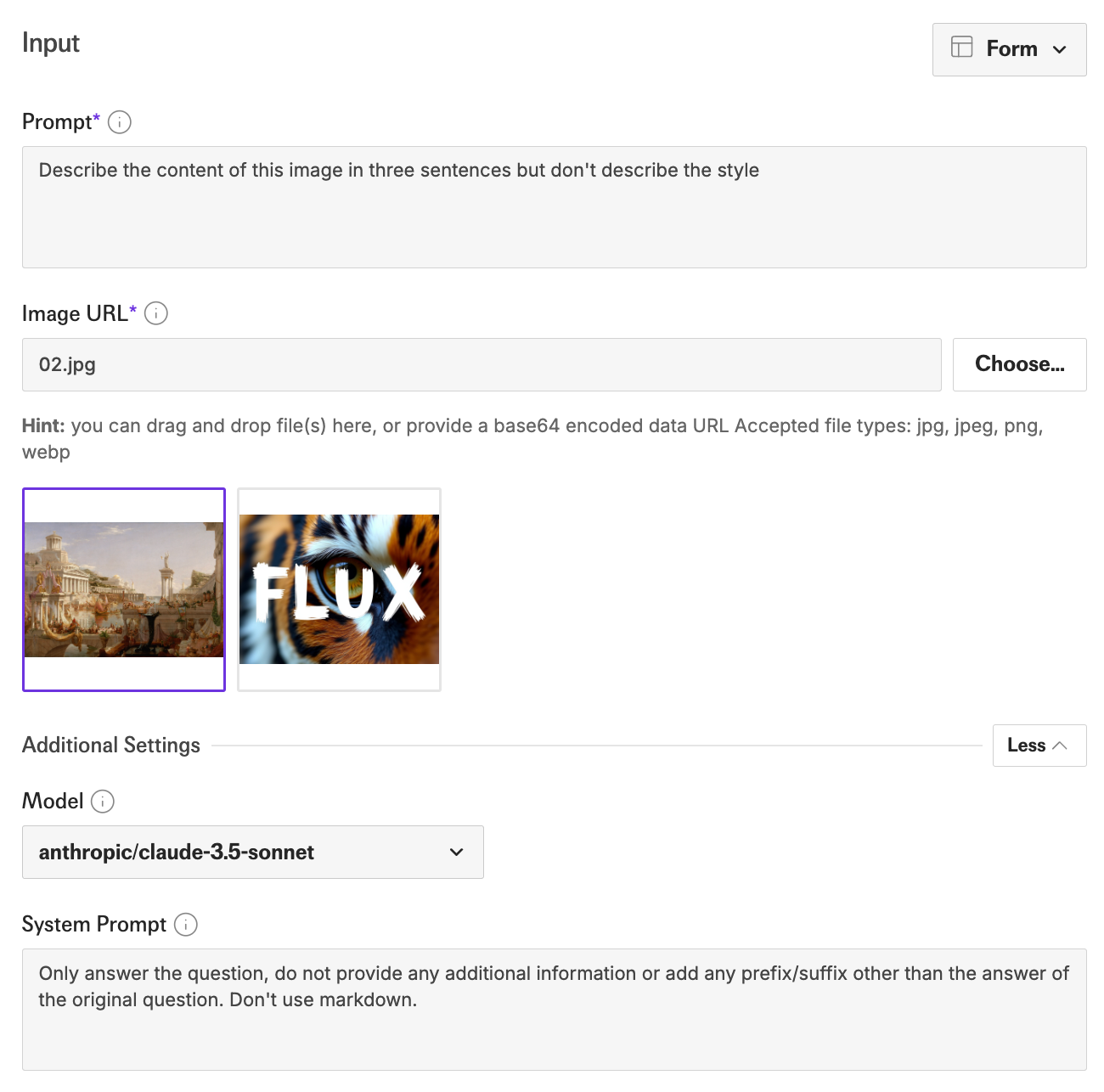
I then appended the caption with “in the style of a tcxl painting”.
Here is an example:

This image depicts a grand cityscape centered around a bustling waterfront, with ornate classical architecture dominating the scene. The foreground showcases impressive structures including a domed circular building and a tall column topped with a statue, while the central area features a water body filled with numerous boats and lined with crowds of people. In the background, the city extends further with more elaborate buildings, including a large hilltop complex, all suggesting a vast and prosperous urban center in classical antiquity. In the style of a txcl painting.
Unfortunately this will weaken the association with txcl painting too much. So we duplicate all of our images and add an additional short caption of just txcl painting.
Here is what our dataset folder looks like. We include .txt files with the same name as our images to provide custom captions:
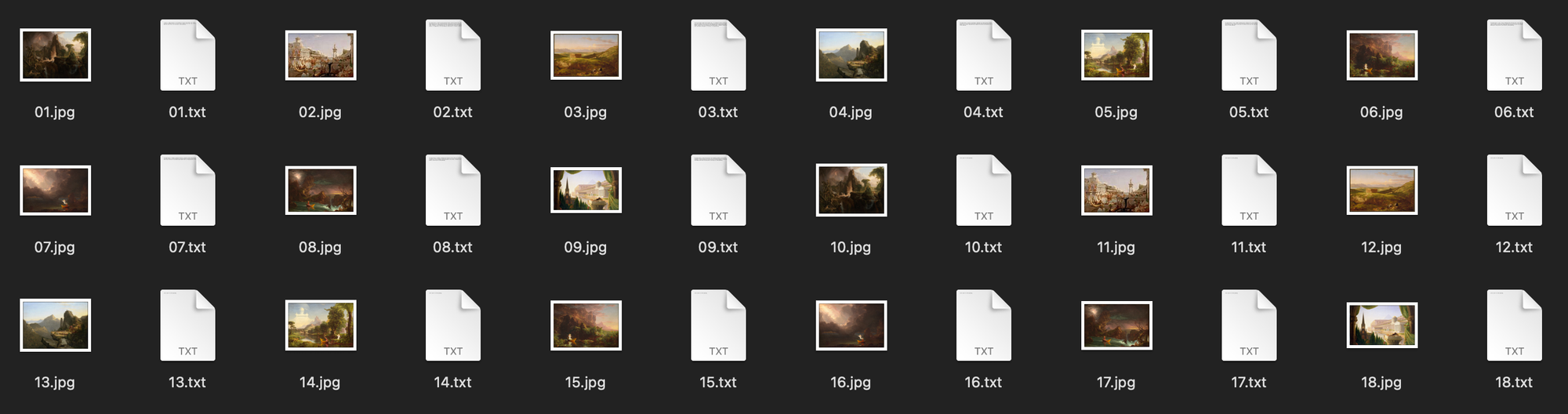
You can see we have duplicated our 9 images and now have 18, so we can caption with both a short and long style.
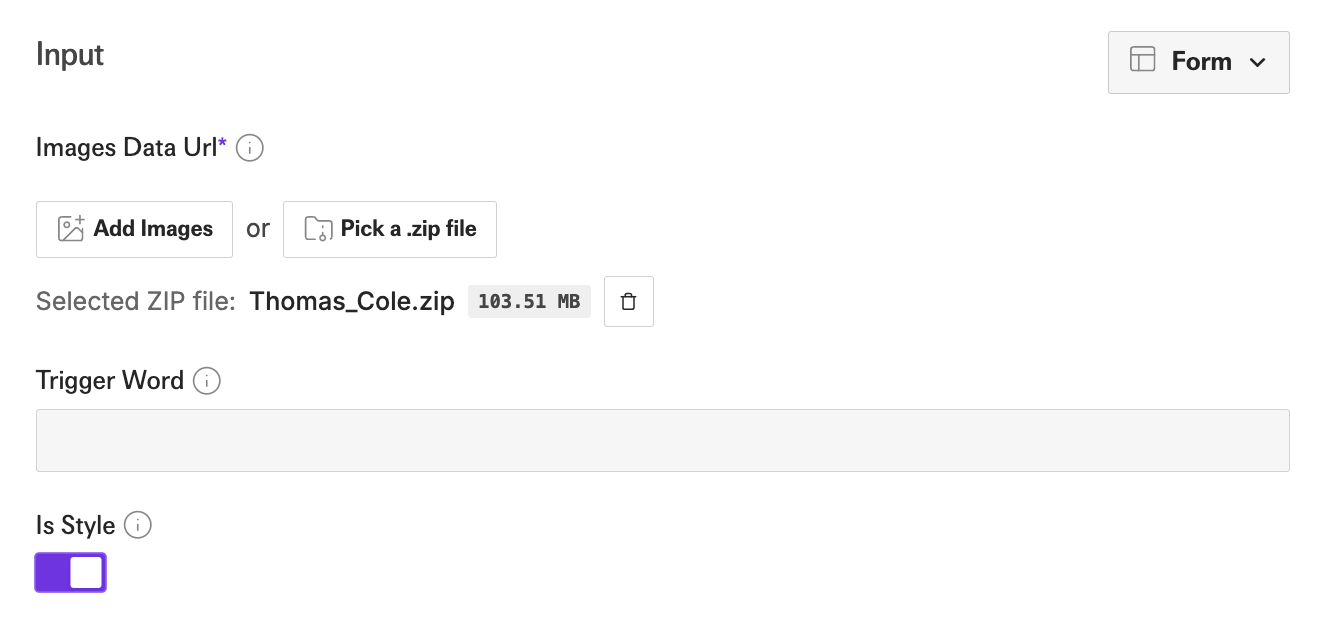
We need to turn this into a zip before using it as input. Here is what our configuration looks like in the playground. We still use is_style but we don’t have to pass a trigger_word any more. It is added in our captions.
Using this approach and 2000 steps we get the following example for laser cat prompt:

Great! We have preserved more style and prompt following.
Personally I liked 1500 steps the best. Here are some examples I made:


In conclusion:
- Grab some images of a style you like and head to https://fal.ai/models/fal-ai/flux-lora-fast-training.
- Upload the image set
is_stylewith atrigger_wordthat is a combination of a unique token and style class description. - Try different steps counts to find a checkpoint you like.
- If you want even more control, try making custom short and long captions.
If you want to try out the final version of the Thomas Cole LoRA you can grab the download link from CivitAI and use it https://fal.ai/models/fal-ai/flux-lora.
Happy training!