Building language model powered pipelines with dbt


Yes, we know… Generative AI is all the hype right now. Whether you are an Analytics Engineer or Data Engineer, you might be wondering if this stuff is only useful for AI generated profile pics, or can I actually use it to help me with my day to day work. Turns out there is a ton of actually useful things you can do with large language models (LLMs), and thereby simplify some complex data pipelines.
In this post, we will go through an example of extracting physical addresses from free-form text fields using a combination of dbt and dbt-fal. We will build a dbt Python model using dbt-fal, which is a dbt adapter that lets us run Python models with all databases (including BigQuery and PostgreSQL). Our Python model will load a deep learning model for Named Entity Recognition. This model will help us extract addresses (and some other useful metadata like persons and organizations) from free-form text. This is a very good use case for when you are trying to extract some named entities (in this case, addresses) from unstructured text. There are many more exciting use cases for deep learning models, and we are excited to explore those over the next weeks.
Why use an LLM instead of regex?
LLMs can be really good at transforming unstructured text into meaningful data. Especially if the model is trained for a specific task. The skeptic in you might claim that extracting data from unstructured text is best done with regular expressions. We all wrote regular expressions that worked 80% of the time and created unexpected bugs, so maybe there is a better way? Some of the benefits of LLMs include the fact that they can capture complex patterns and generalize to unseen data. You can also handle multiple data types and fine-tune your model to suit your needs.
Getting Started
pip install dbt-fal["bigquery"] # You can use snowflake or postgres here
We then start a new dbt project by running dbt init. We also configure our profiles.yml file for dbt to correctly use the dbt-fal adapter. You can find the instructions here.
Create raw data and seed it
We now want to create a CSV file with some free-form text. This is for illustrative purposes. In a real-world use case, this would most likely be another upstream table.
free_form_text.csv looks like this:
sentences
My name is Jane and I live in San Francisco
My name is Burkay and I live in New York
My name is Alicia and I live in London
My name is John and I live in Berlin
To load the data into your data warehouse, run dbt seed.
Define a new Python environment
The Python model that we will create needs some dependencies to run successfully. One way to achieve this is to install these dependencies locally (assuming dbt is running locally), but we recommend using fal environments for production settings.
To use fal environments, we create a fal_project.yml file to define a new environment called named_entity_recognition. This is a very useful feature from dbt-fal that allows us to create reusable, isolated Python environments. Our fal_project.yml file looks like this:
environments:
- name: named_entity_recognition
type: venv
requirements:
- transformers
- torch
- accelerate
- datasets
- pandas
Here we include all the dependencies that our ML model will need. These are transfomers, torch, accelerate, datasets and pandas
Create a new Python model that will extract addresses
Now we get to the crux of this tutorial where we create a Python model called extracted_addresses.py which will extract addresses from the free-form text. This model loads a Named Entity Recognition ML model hosted on Hugging Face and then processes the upstream table with the example sentences. It then outputs the results into a table called extracted_addresses.
def model(dbt, fal):
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
from pathlib import Path
from datasets import Dataset
import pandas as pd
dbt.config(fal_environment="named_entity_recognition")
cache_dir = Path("/data/huggingface/large-ner").expanduser()
cache_dir.mkdir(parents=True, exist_ok=True)
tokenizer = AutoTokenizer.from_pretrained("dslim/bert-large-NER")
model = AutoModelForTokenClassification.from_pretrained(
"dslim/bert-large-NER", cache_dir=cache_dir
)
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
df = dbt.ref("free_form_text")
dataset = Dataset.from_pandas(df)
ner_results = nlp(dataset["sentences"])
return pd.DataFrame({"results" : ner_results})
Run dbt!
Now that everything is ready, we can run our pipeline with dbt run. The first time you run it might take some time since dbt-fal will install all the required packages. Following runs will be very fast as the environment is cached. You will get a table like this:
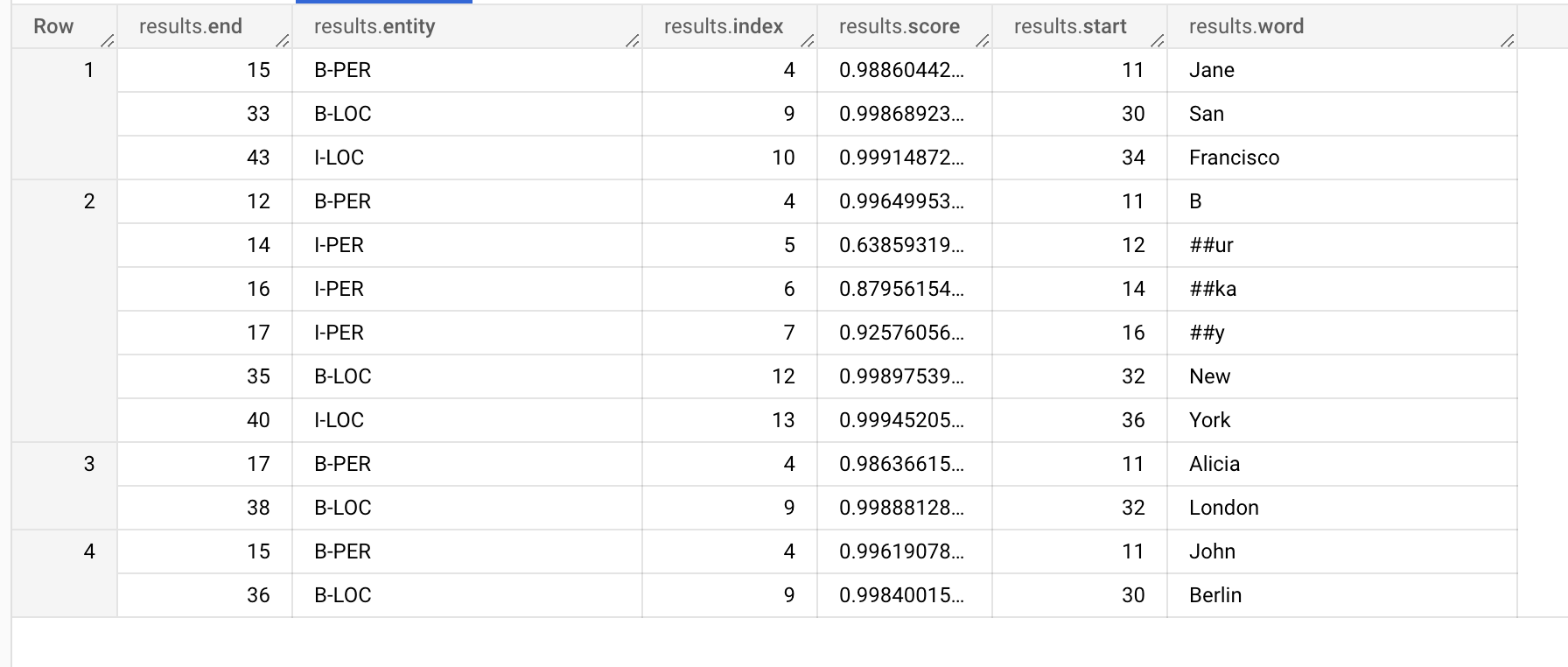
These results are a bit cryptic, but let’s dive in to see whether we can make sense out of them. Here, each Row represents the entities that were extracted from a given sentence. Let’s look at Row 1:

For the input sentence “My name is Jane and I live in San Francisco", the ML model has identified three entities: “Jane”, “San” and “Francisco”.
“Jane” (as denoted by the results.word column) is a B-PER entity (as denoted by the results.entity column) which means that she is a “Person”. result.start and result.end tells us where the string in the original sentence starts and ends, in the case of “Jane”, the word is at the 11th to 15th index in the sentence. Similarly “San” and “Francisco” are parts of a “Location” entity where B-LOC denotes the beginning of the location word and I-LOC denotes that the word is continuing and is also a “Location”.
Let’s make things faster. dbt using GPUs!
If you got this far and successfully ran this example, you might notice that it is a little slow or it did not run at all (if you have a slow computer). This is because we are running all Python models in dbt-fal locally by default, and these LLMs typically require more compute resources to run efficiently. Now comes the cool part. With a tiny change in our dbt-fal configuration, we can now use GPUs in the cloud to run this model much faster.
In order to do this, change profiles.yml to add your fal-serverless keys (reach out to us if you want access)
default:
outputs:
production:
db_profile: warehouse
type: fal
host: REACH_OUT_TO_FAL_TEAM_TO_ACCESS
key_id: REACH_OUT_TO_FAL_TEAM_TO_ACCESS
key_secret: REACH_OUT_TO_FAL_TEAM_TO_ACCESS
Add machine configuration to your model, and don’t forget to run the Hugging Face pipeline on top of the GPU device.
def model(dbt, fal):
...
dbt.config(fal_environment="named_entity_recognition", fal_machine="GPU")
...
nlp = pipeline("ner", model=model, tokenizer=tokenizer, device="cuda:0")
...
Magical! With a few config changes, we are able to go from running dbt-fal locally to running it in the cloud with GPUs when we need the performance to scale to larger datasets.
Summary
In this post, we went over a practical use case for using language models for Analytics Engineering workloads where we extract addresses from free-form text. We started with a local dbt-fal project, we iterated locally, and we pushed our workload to a GPU machine in the cloud with almost no effort.
To find the working code example, you can go here. If you want access to fal-serverless, don’t hesitate to reach out to us at hello@fal.ai.
We would love to hear more from you regarding AI! What else would you like to solve with it? Let us know in #tools-fal channel on dbt Slack and don’t forget to star our Github repo.