Introducing Qwen Image


We are proud to announce fal's inference and training endpoints Alibaba's Qwen Image model.
It is has been an incredible month for generative media. We've been blessed not one, but two unbelievable high quality image models Wan 2.2 14b and Qwen Image.
I went into Wan 2.2 14b in the last blog, but Qwen came out merely a day after is amazing in some unique ways.
Builtin Styles
The incredible prompt following leads to impressive style representation and text rendering.

In general, image models are not able to generate precise styles. The difference between a "painting" and "impressionist painting" is often barely noticeable in other models, but Qwen Image has a much more nuanced understanding of art styles.
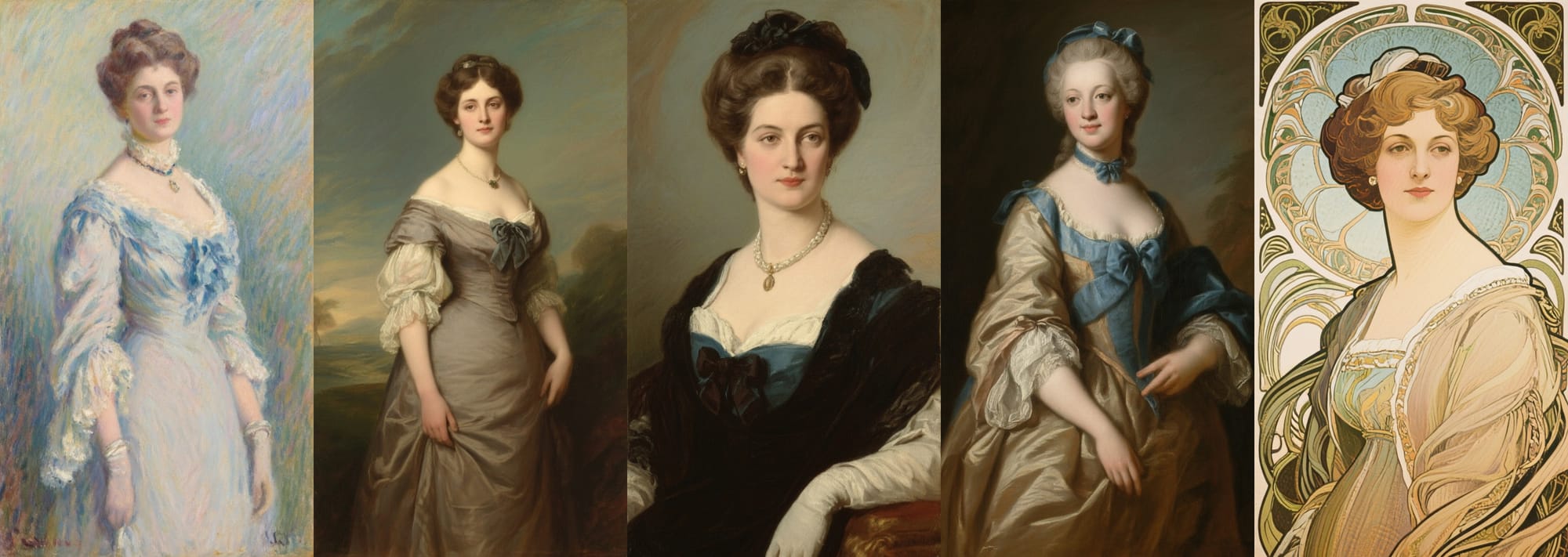
In addition a more diverse and accurate palette of styles, Qwen Image excels at intricate text rendering.
Compared to other popular image generators, Qwen Image can render text that follows the prompt much better in complex scenes.

Personalization
Using the newly released fal Qwen Image Trainer, we can create high quality personalized generations with a handful of images.
Here I have used seven iPhone headshots to create a LoRA of my face. You can see below that Qwen Image was able to generate an accurate and high quality portrait with the resultant LoRA.

Not only does it do a great job with headshots, but it can preserve identity with more complex prompts as well.

Custom Styles
Although Qwen Image can generate an absurd amount of styles out of the box, sometimes it is necessary to make a custom style LoRA to augment its abilities. This is especially true of obscure styles that don't have an readily available name one can use when prompting.
Here I have trained 1980s luxury interior design LoRA. You can see, Qwen Image does a pretty good job without the LoRA, but the LoRA makes it washed out, adds film grain and cigarette smoke which gives it that authentic 80s feel.

Open source is Cooking
Qwen Image is incredible model for text to image. We at fal can't wait to see what the community comes up with using it. Try out the inference and training with the links below.
Inference: https://fal.ai/models/fal-ai/qwen-image