Building Applications with Real-Time Stable Diffusion APIs


In this blog post we would like to showcase fal’s real-time Stable Diffusion APIs that are powered by Latent Consistency Models (LCMs). These models have been getting a lot of hype lately because they allow you to generate images very quickly around 150ms as opposed to 10 seconds with vanilla Stable Diffusion.
In the past couple of days, these APIs helped us build a couple of demo apps, such as fal.ai/dynamic, which allow users to draw AI generated images in real time. Working together with ilumine AI we helped build the #1 trending LCM-Painter space on HuggingFace. We also worked on demo implementations with Figma and tldraw. Because of the overwhelming attention from both end-users and developers, we decided to write a post about how to build a similar app. So, let's dive in!
Introduction to REST API
The REST API for LCM is designed to be simple and intuitive. It works by accepting POST requests, with the data being sent in JSON format. Here’s the URL:
https://110602490-lcm-sd15-i2i.gateway.alpha.fal.ai/
You can easily make a request by using the curl command:
curl --request POST \
--url https://110602490-lcm-sd15-i2i.gateway.alpha.fal.ai/ \
--header "Authorization: Key $FAL_KEY_ID:$FAL_KEY_SECRET" \
--header 'Content-Type: application/json' \
--data '{
"prompt": "an island near sea, with seagulls, moon shining over the sea, light house, boats in the background, fish flying over the sea",
"image_url": "https://storage.googleapis.com/falserverless/model_tests/lcm/source_image.png"
}'If you don’t already have your fal credentials, you can get them by logging into https://fal.ai.
In the above example we’re sending a JSON object with two parameters: prompt and image_url. The image URL can also be a base64 encoded image URL. The API also accepts more parameters than just the prompt, which allow you to better control the image generation process. For more information, see you our LCM model documentation
The output of this model is also a JSON object. Here's a sample response:
{
"images": [
{
"url": "",
"width": 0,
"height": 0,
"content_type": "image/jpeg"
}
],
"seed": 0,
"num_inference_steps": 4,
"request_id": ""
}
In the response, the images field is an array of objects, each representing a generated image. Each image object includes a url field, which is the link to the generated image.
Using fal JS Client
fal has a powerful JavaScript client that simplifies interactions with its API endpoints. To begin, you need to install the fal JS client library in your project:
npm install --save @fal-ai/serverless-client
Once the library is installed, you need to configure it with your fal credentials. This is done by importing the fal module and calling the config function with your credentials. Here's an example:
import * as fal from '@fal-ai/serverless-client';
fal.config({
credentials: 'FAL_KEY_ID:FAL_KEY_SECRET',
});
With the client configured, you can now make requests to the fal API. The run method is used to call the LCM API. This function takes an input object that specifies the parameters for the API call. Here's an example:
const result = await fal.run("110602490-lcm-sd15-i2i", {
input: {
image_url: imageDataUri,
prompt: PROMPT
}
});
If successful, the result object should have at least one image in result.images, so you can access it via result.images[0].url.
Note that it’s not a good idea to publish your fal credentials in a front end application. In order to mitigate this we’ve released a client proxy package that works with Next.js and Express. For more information see here.
We collaborated with the fine folks at tldraw to build real-time image generation right into their collaborative canvas as you can see in the demo above. To see the detailed implementation, check out the code here.
Optimizing Model Performance Further
So far, we have done our experiments with SDv1.5 only. We also wanted to test how SDXL behaves as well in terms of latencies as well as image quality, so we built another endpoint which allows users to specify the model to be used for image generation.
From our performance comparisons, we have found that the SDv1.5 model generally produces superior results compared to the SDXL in terms of image quality for handdrawn image inputs.
This was observed when the same input image, seed, number of inference steps, and guidance scale were used. Not only does the Stable Diffusion v 1.5 model yield better results, but it also does so faster. In our tests, with four inference steps, the Stable Diffusion XL model took 650ms, while the Stable Diffusion v 1.5 model completed the same task in 355ms end-to-end (including network overhead) of which 120ms accounts for GPU inference time.
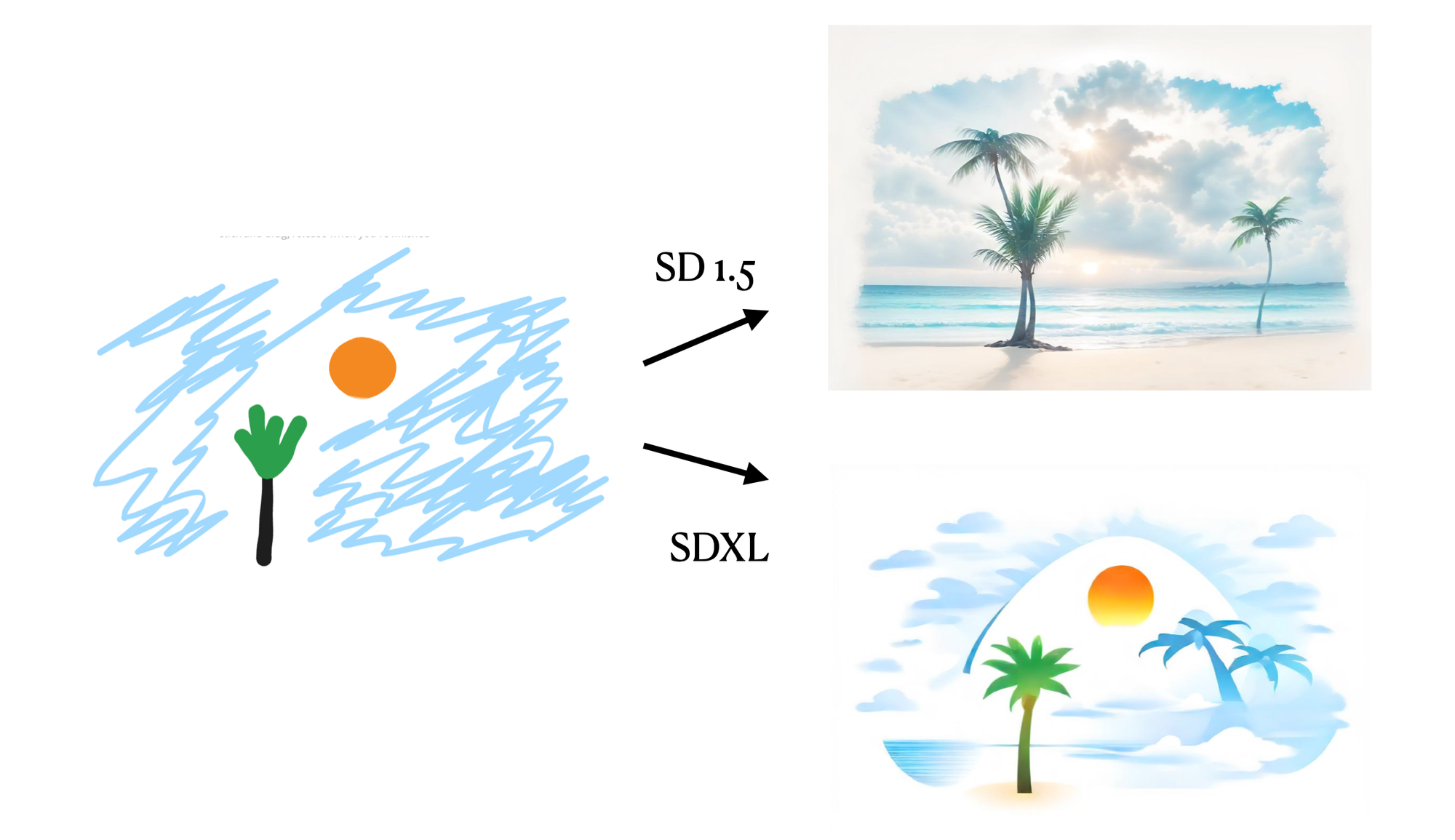
In addition to choosing the right model, users can further enhance the speed of the API by providing images as base64 encoded data URIs instead of URLs. The server is significantly faster at processing base64 images compared to downloading images from the internet. Same goes for the output images as well. In our experiments, this results in a latency reduction of 200-300 ms, making the API suitable for real-time use cases.
Using WebSockets
With all optimizations we can reach 2-3 frames per second with REST API. What if we want to push it further? This can be achieved by using WebSockets, that let us get to 3-5 frames per second. The fal JS client doesn’t yet support WebSockets and we are working hard to make this happen as soon as possible. In the meantime, here’s how you can build your own client.
To set up a WebSocket connection with the LCM API, you first need to establish a connection to the appropriate WebSocket URL. Here's how you can do it in React:
const URL = "wss://110602490-lcm-sd15-i2i.gateway.alpha.fal.ai/ws";
const webSocketRef = useRef<WebSocket | null>(null);
const connect = useCallback(() => {
webSocketRef.current = new WebSocket(URL);
...
}, []);
Once the WebSocket connection is established, we need to handle the various events that can occur during a WebSocket session. These include onopen, onclose, onerror, and onmessage. Here's how we handle these events:
webSocketRef.current.onopen = () => {
options.onOpen?.();
};
webSocketRef.current.onclose = () => {
options.onClose?.();
};
webSocketRef.current.onerror = (error: Event) => {
options.onError?.(error);
};
webSocketRef.current.onmessage = (message: MessageEvent) => {
options.onMessage?.(message);
};
To send messages to the server via WebSocket, we use the send method of the WebSocket instance:
const sendMessage = useCallback(async (message: string) => {
...
webSocketRef.current?.send(message);
}, []);
When the server sends a message, the onmessage event is triggered, and the corresponding handler is called. In our case, we parse the message data and update the image and inference time accordingly:
onMessage: (message) => {
try {
const data = JSON.parse(message.data);
if (data.images && data.images.length > 0 && data.images[0].url) {
setImage(data.images[0].url);
setInferenceTime(data.timings?.inference || NaN);
}
} catch (e) {
console.error("Error parsing the WebSocket response:", e);
}
},
Finally, when the component unmounts or when we no longer need the WebSocket connection, we close it using the close method:
const disconnect = useCallback(() => {
webSocketRef.current?.close();
}, []);
Here's a demo of our dynamic app that uses WebSockets:
This video is not sped up
You can find a simple implementation of a React app that uses LCM over WebSockets here. In this example, we also made additional optimizations such as reusing Websocket connections to make each inference request around 250ms or less.
Conclusion
In summary, we've explored how to leverage fal’s real-time Stable Diffusion endpoints using both REST APIs and WebSockets. The former provides a straightforward interaction method, while the latter opens up real-time, two-way communication, enhancing the user experience in applications demanding immediate updates.
At fal, we are excited about the new possibilities of generative AI and can’t wait to see what our technology enables. If you have any questions or run into any issues, reach out to us in our discord server.
We would like to thank the authors of the LCM paper for their epic work.